Citizen Science: first observations¶
At a glance
Register, log in, upload your first deployment, and review the AI-processed results in the Citizen Science frontend.
- Time: ~20 minutes plus upload time
- Who: new Citizen Science users — researchers, volunteers, NGO/park staff
- Prerequisites: an invitation to (or visibility of) a project on your TRAPPER instance
Getting started¶
1. Create an account¶
On the main login page, click the Create an account button to open the registration form.
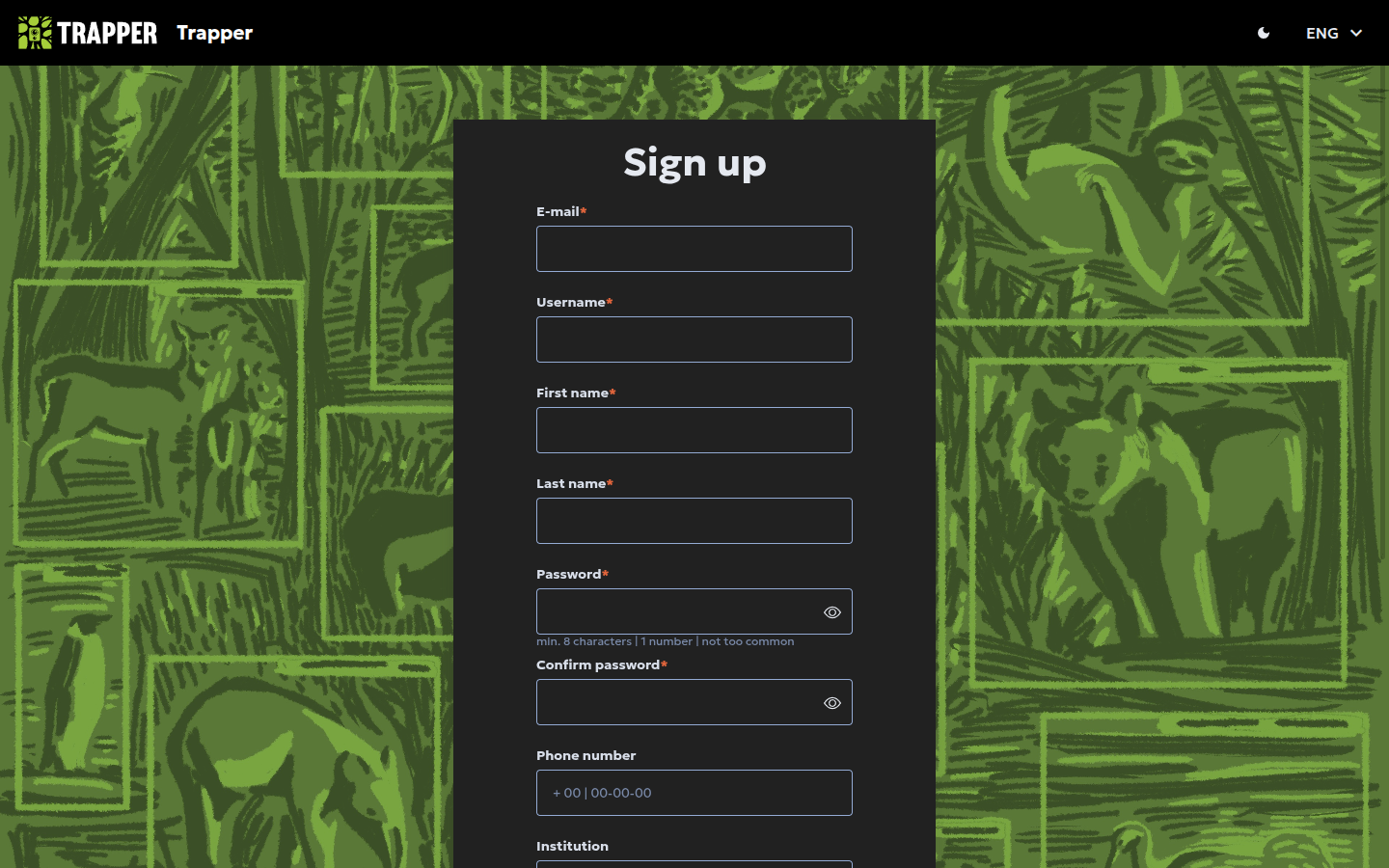
- Fill in your E-mail, Username, First name, Last name, Password (and Confirm password). Phone number, Institution, and About me are optional.
- Review and agree to the Terms of Service and Privacy Policy.
- Click the final Create an account button to submit.
Important
After registering, check your email inbox for a verification link to activate your account. You can't log in until you've completed this step.
Note
If you already have an account in the Trapper Expert module, you can log in to the Citizen Science interface using the same email and password — no separate registration is required. If you still can't access a project, ask your project administrator to grant the necessary permissions.
2. Log in¶
Once your account is activated, sign in.
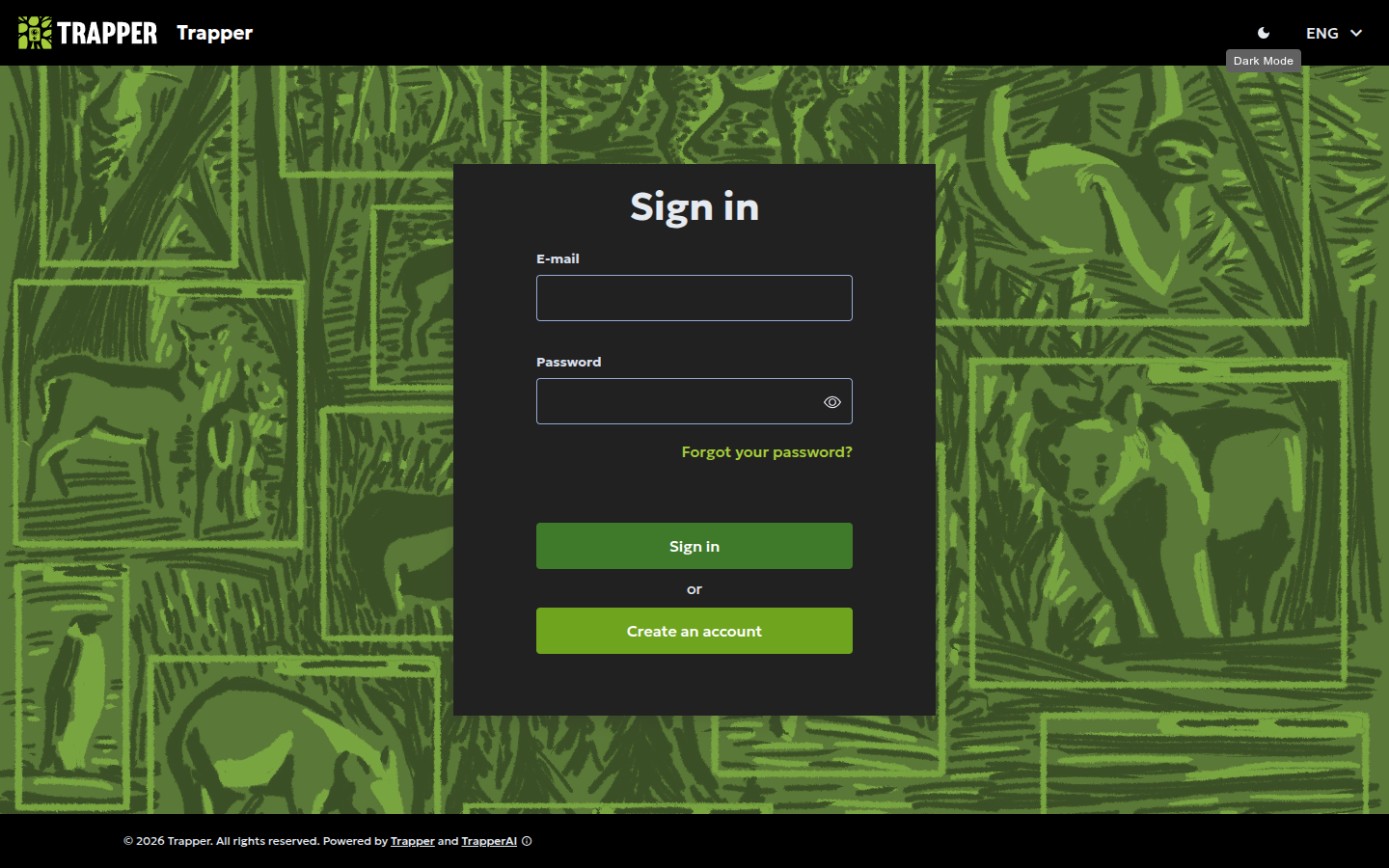
- Navigate to the Trapper login page.
- Enter your E-mail and Password.
- Click the Sign in button.
Note
You can also sign in using a Google or Microsoft account. These social login options must be configured in advance by an administrator in the Trapper Expert admin panel.
The main dashboard¶
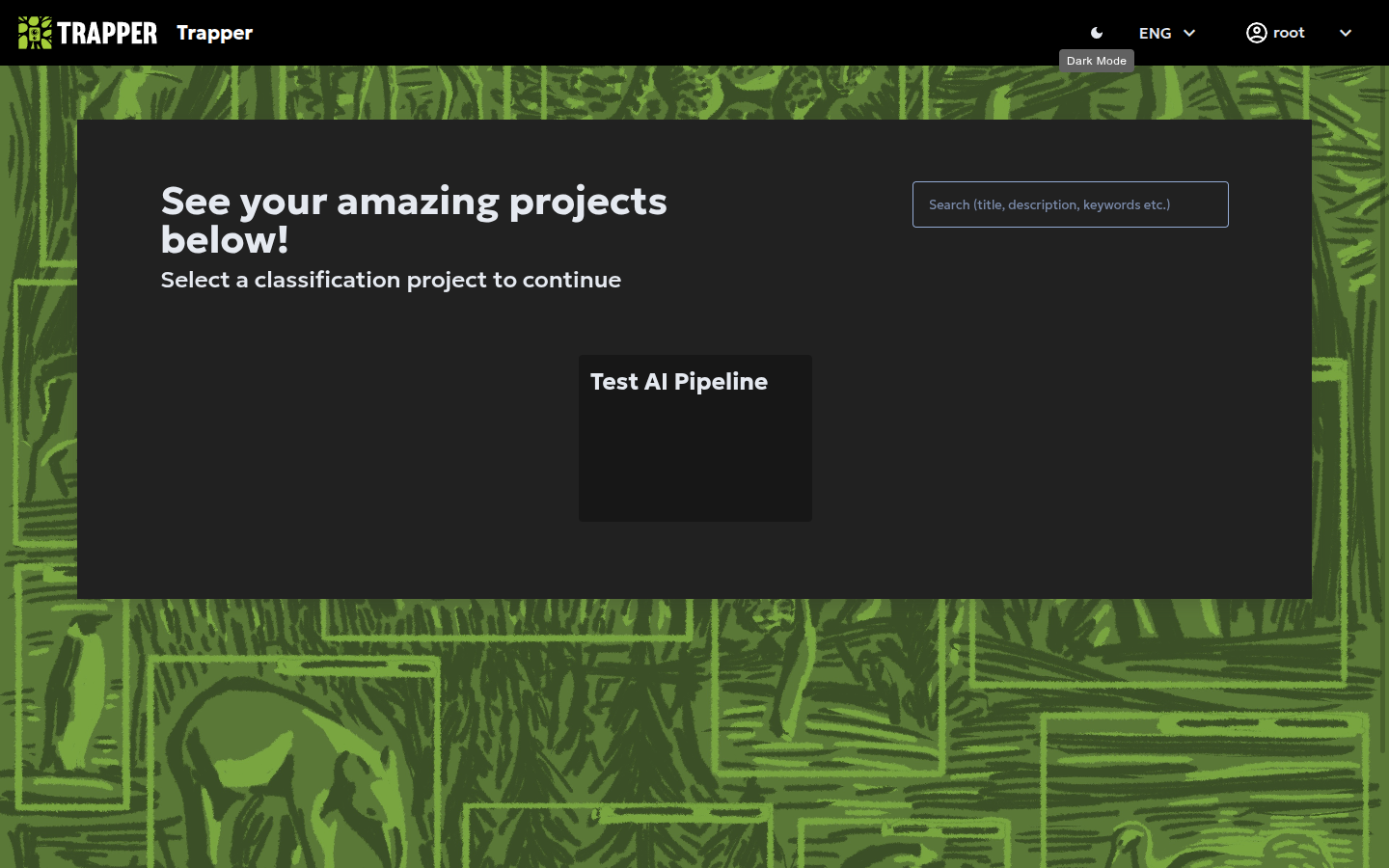
After logging in you land on the Citizen Science project selection page — your central hub for all the projects you're a member of. Click on the project you wish to access.
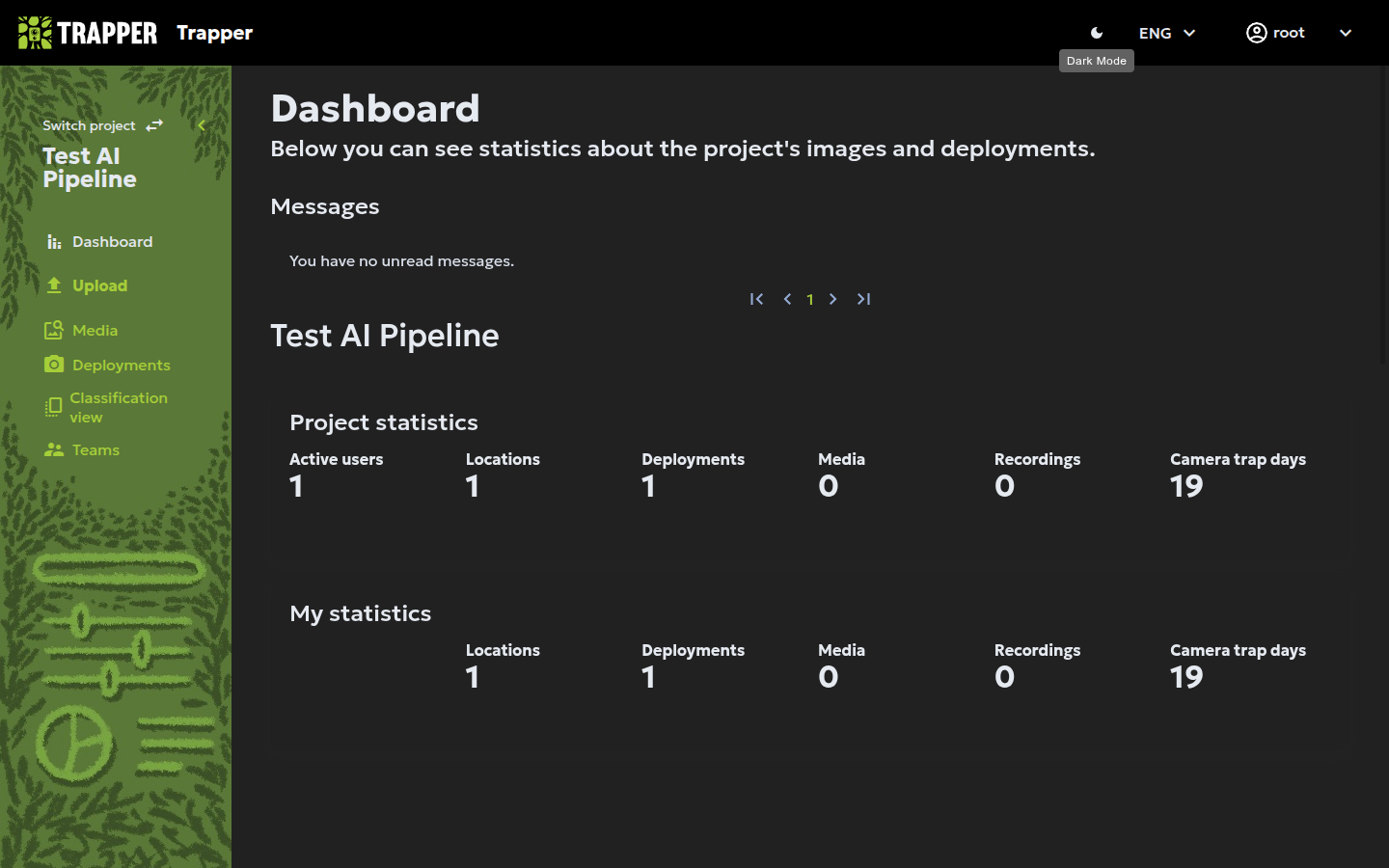
Once you enter a project, you'll see the project's dashboard, which gives you a quick statistical overview, including the number of locations, deployments, media files, recordings, and camera traps. You can also see a bar chart that visualizes the distribution of species identified, providing an immediate insight into the biodiversity captured.
Uploading camera trap media¶
Uploading your images and videos is the first step in analyzing your data. Our uploader is designed to capture all the necessary metadata for a successful deployment.
Step 1: Start a new upload¶
From the main navigation menu, go to the Upload section. This will take you to the upload form.
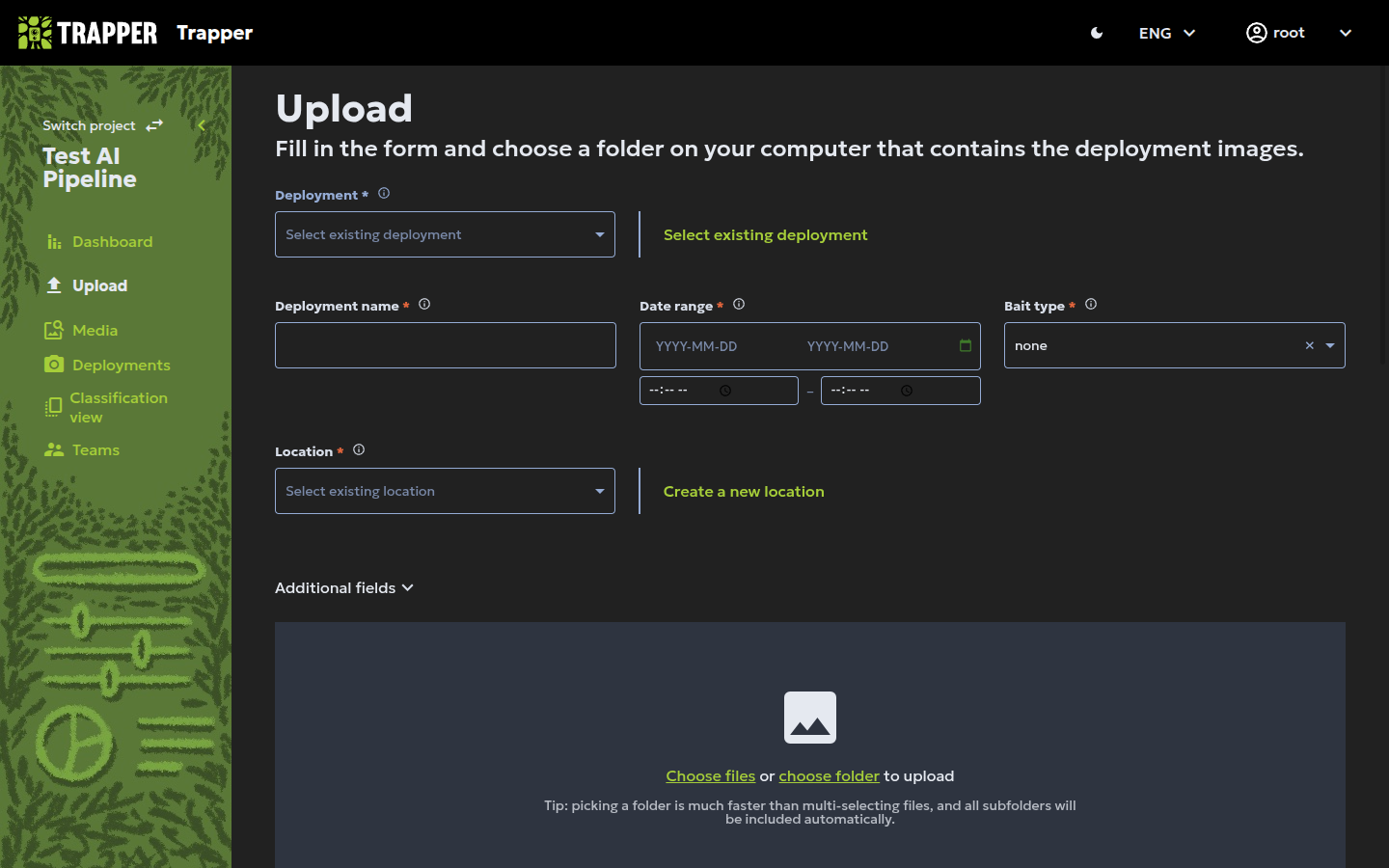
Step 2: Add deployment details¶
What is a deployment?
A deployment is the period during which a camera trap is installed at a given location and actively recording, typically without being moved or significantly altered.
Ecologically, a deployment represents a continuous sampling event, capturing all wildlife activity within the camera's detection zone for the defined time span. Each deployment is uniquely identified by its combination of location, time interval, and camera setup, and is fundamental for linking collected media and metadata to ecological analyses such as species occurrence, activity patterns, and habitat use. Read more.
Fill in the basic deployment fields:
| Field | What it does | Example |
|---|---|---|
| Deployment name | Unique, descriptive identifier | bialowieza_lcm_2025 |
| Date range | Start/end of the deployment | Aug 1 – Sep 23, 2025 |
| Bait type | If any bait was used | none for most scientific studies |
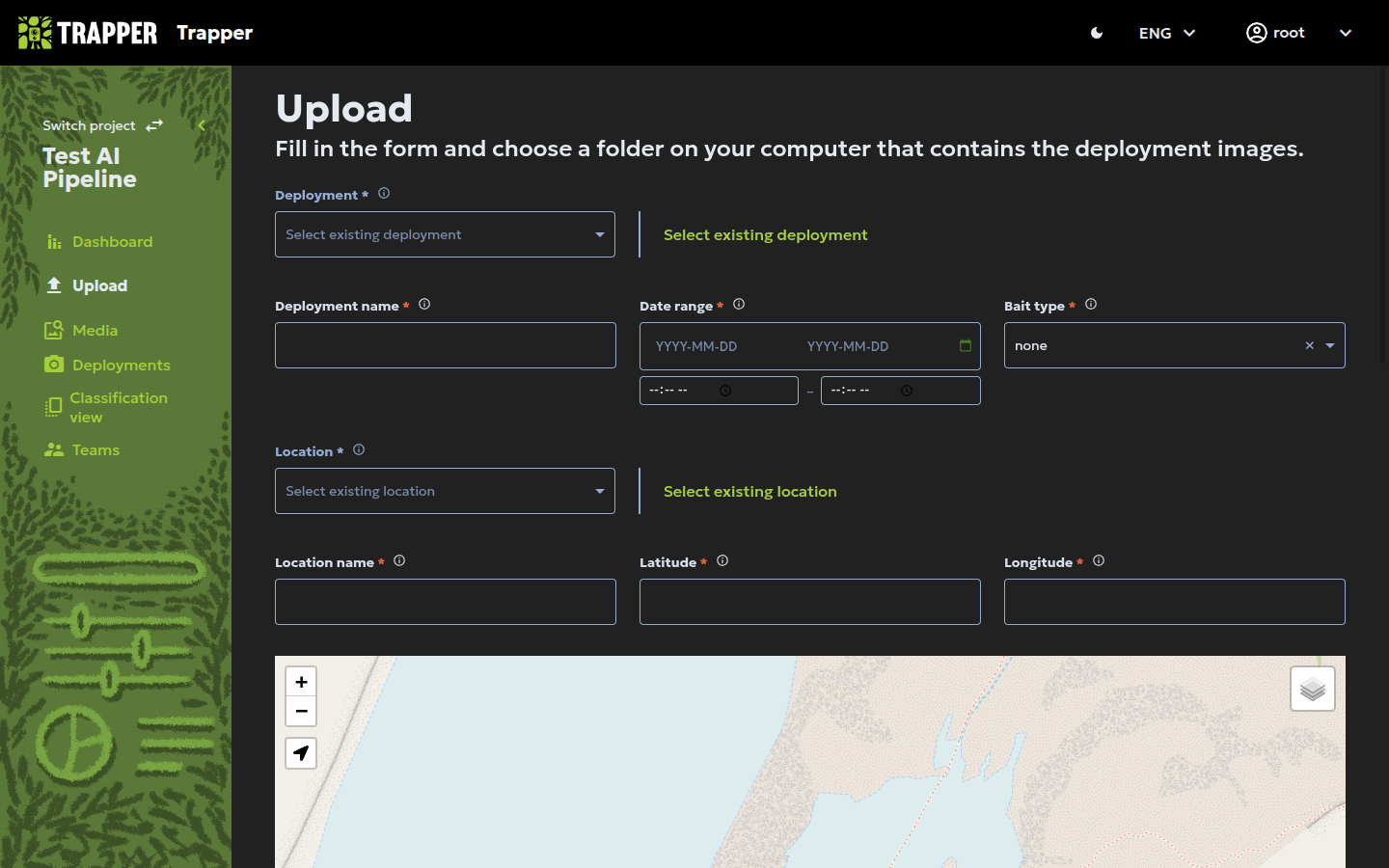
Step 3: Set the location¶
Accurate location data is crucial. You can select an existing location or create a new one.
- Click Create a new location.
- Enter a Location name (e.g.
bialowieza_loc1). - Set coordinates: click on the map to place a pin at the exact location of your camera. Zoom in for greater precision — latitude and longitude will fill in automatically.
Note
By default, the Deployment name (code) is combined with the Location name to create a unique deployment identifier — the whole value is slugified (lowercased, spaces → dashes), and the project ID is the classification project's:
slugify({deployment_name}-{classification_project_id}-{user_id}-{location_name})
Custom deployment names and IDs can be provided via the Expert module — either by creating deployments manually or by importing a CSV file in the Camtrap DP format (see Import locations & deployments). The only requirement is that each deployment ID be unique within its project. Deployments added this way become available in the upload form for users with the appropriate permissions.
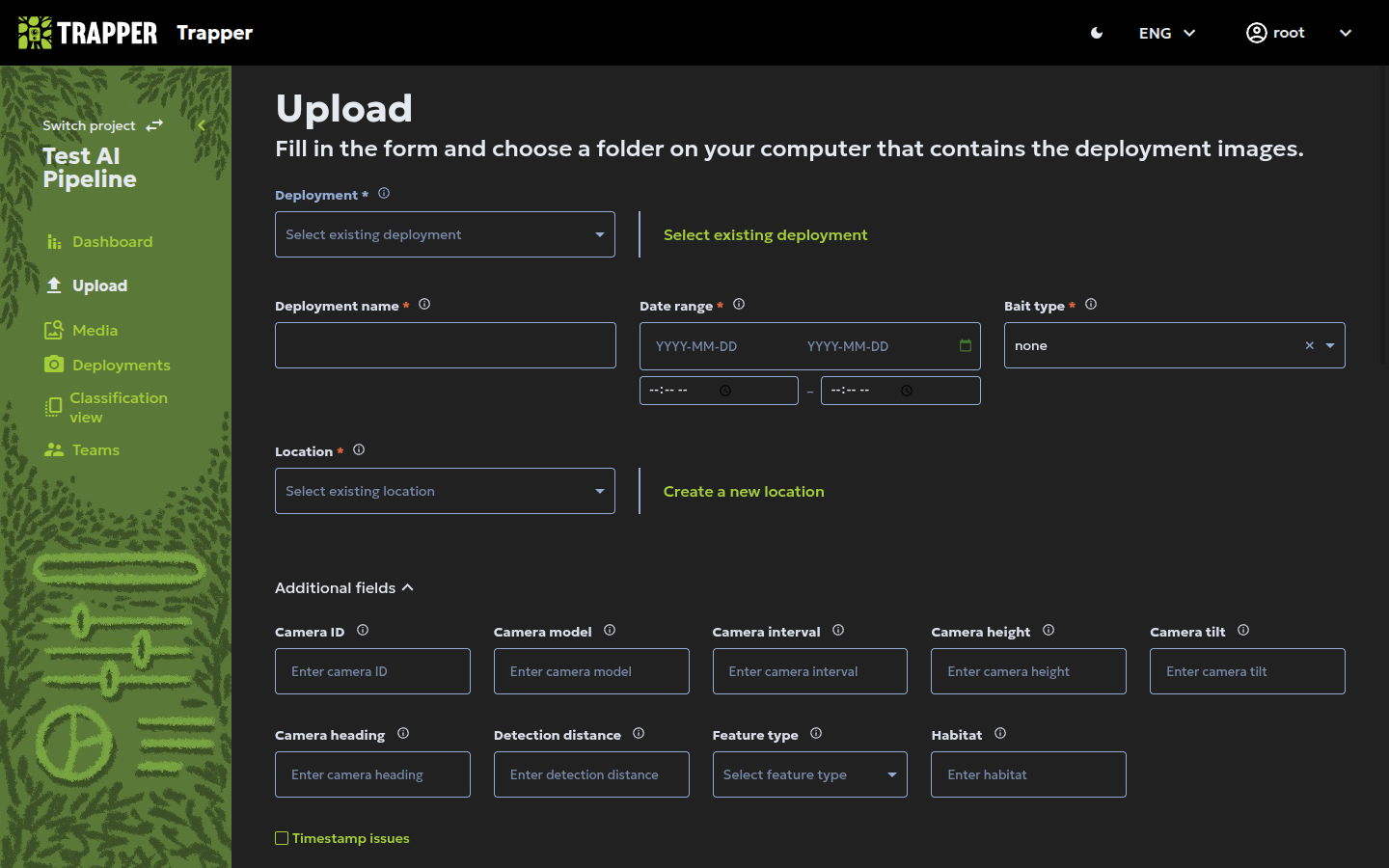
Step 4: Camera and additional metadata (optional but recommended)¶
While optional, detailed metadata makes your data significantly more valuable for scientific analysis. More data is always better.
| Field | Example |
|---|---|
| Camera model | browning_btc6 |
| Camera ID | camera1 |
| Camera interval | 0 seconds between triggers |
| Camera height | 1.2 m |
| Camera tilt | -10 for a slight downward tilt; 0 = parallel to ground |
| Camera heading | 270 (compass degrees, West) |
| Detection distance | 20m estimated effective sensor range |
| Feature type | Road dirt, Water source, Carcass |
| Habitat | mixed forest, riparian zone |
| Timestamp issues | Check if the camera's clock was known to be wrong |
| Comments | Free text — e.g. "Camera knocked by a boar on Sept 15th" |
Camtrap DP compatible
Data Standardization: All the deployment metadata fields in Trapper, from camera settings to location data, are fully compatible with the Camera Trap Data Package (Camtrap DP) standard. This ensures that your data is structured, interoperable, and ready for sharing with global biodiversity platforms. You can learn more at the official Camtrap DP website
Step 5: Upload your files¶
Now it's time to add your media!
- Click the Drag & drop or choose file to upload area.
- Navigate to the folder on your computer containing your images or videos.
- Select all the files you want to upload and confirm. You can select multiple files at once.
- A progress bar will appear showing the status of your upload. Wait for it to complete.
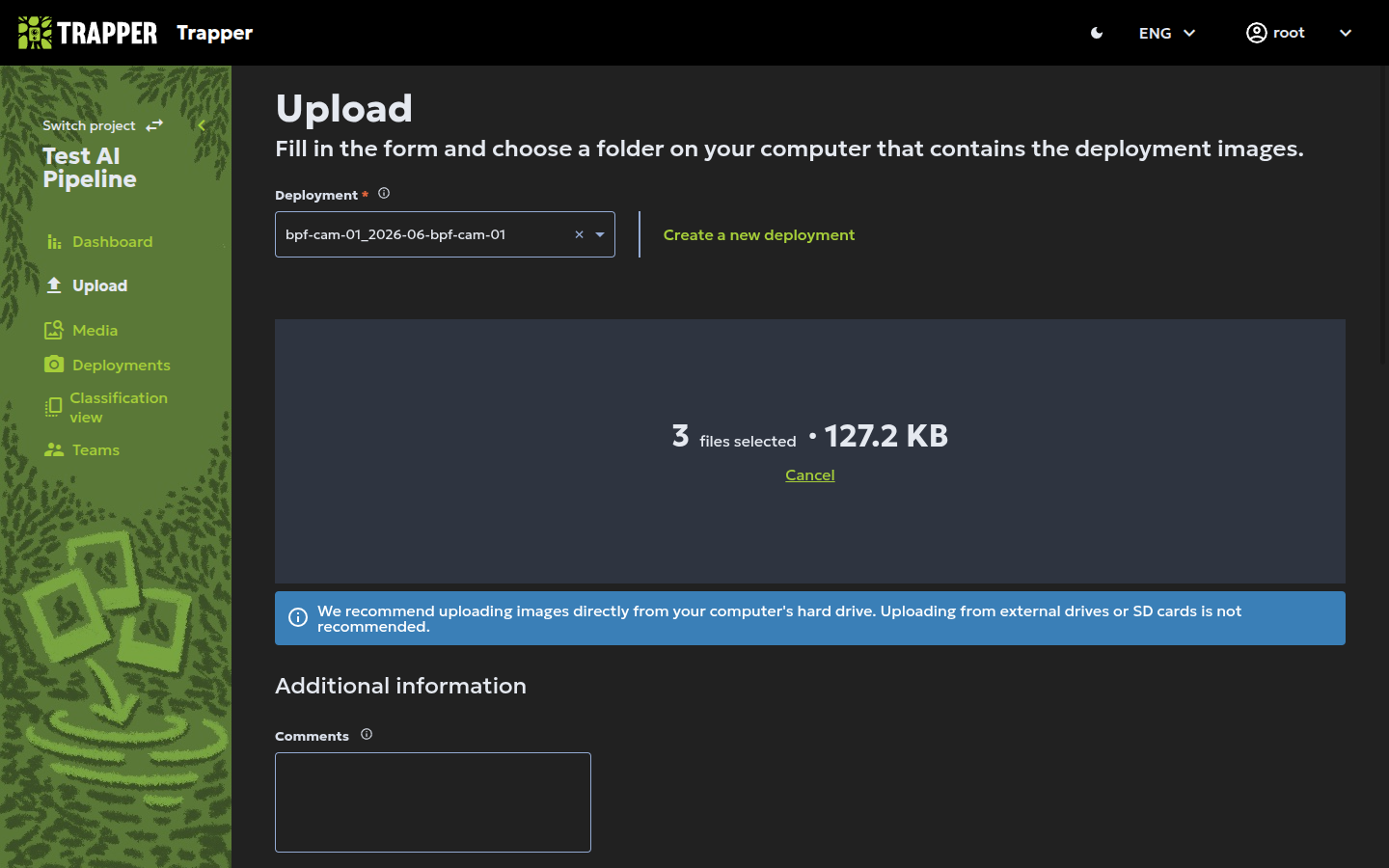
Automatic AI processing
Once your files are successfully uploaded, they automatically enter an AI data processing pipeline. This pipeline, which may include object detection and species identification models, is configured in the project's Classification Project settings. For more details on configuring this pipeline, please see the Classification project administration. To learn more about the automatic pipeline workflow see the Automatic AI Pipeline Workflow.
Viewing your data¶
Deployment summary¶
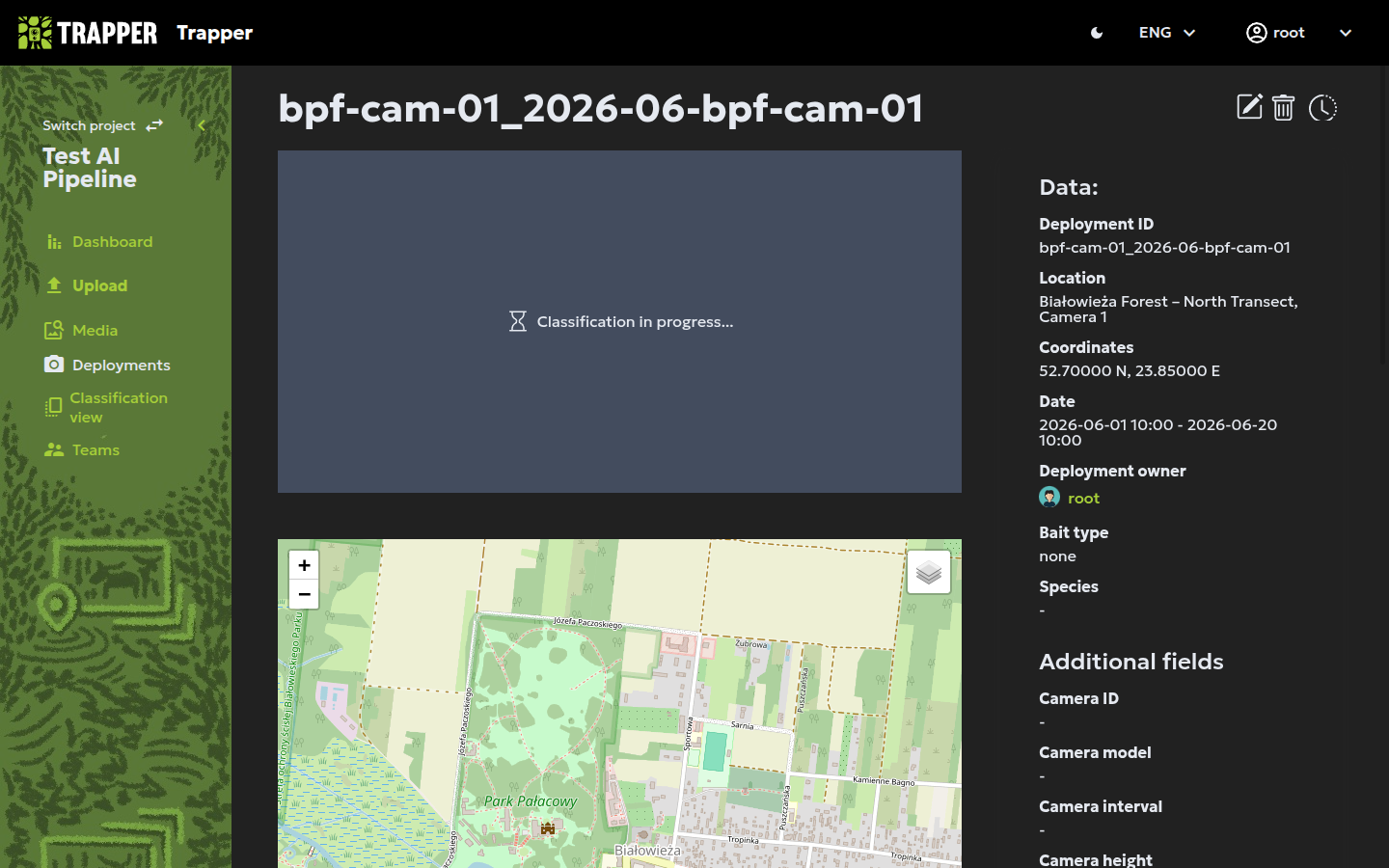
Once the upload and initial processing finish, you will be redirected to the Deployment Summary page. There you can view:
- A data panel displaying all entered metadata, including the deployment ID, location, coordinates, date range, and deployment owner.
- A gallery of the images you uploaded. The system will display "Classification in progress…" while the AI analyzes your media.
- An interactive map showing the deployment location; you can zoom in and out to examine it in greater detail.
- Additional information, such as extra metadata fields, comments, and options to mark images as private or to flag an incomplete deployment.
- Statistics about the processed data, including resources processed by object detection and species models, resources you classified, and resources classified by other experts.
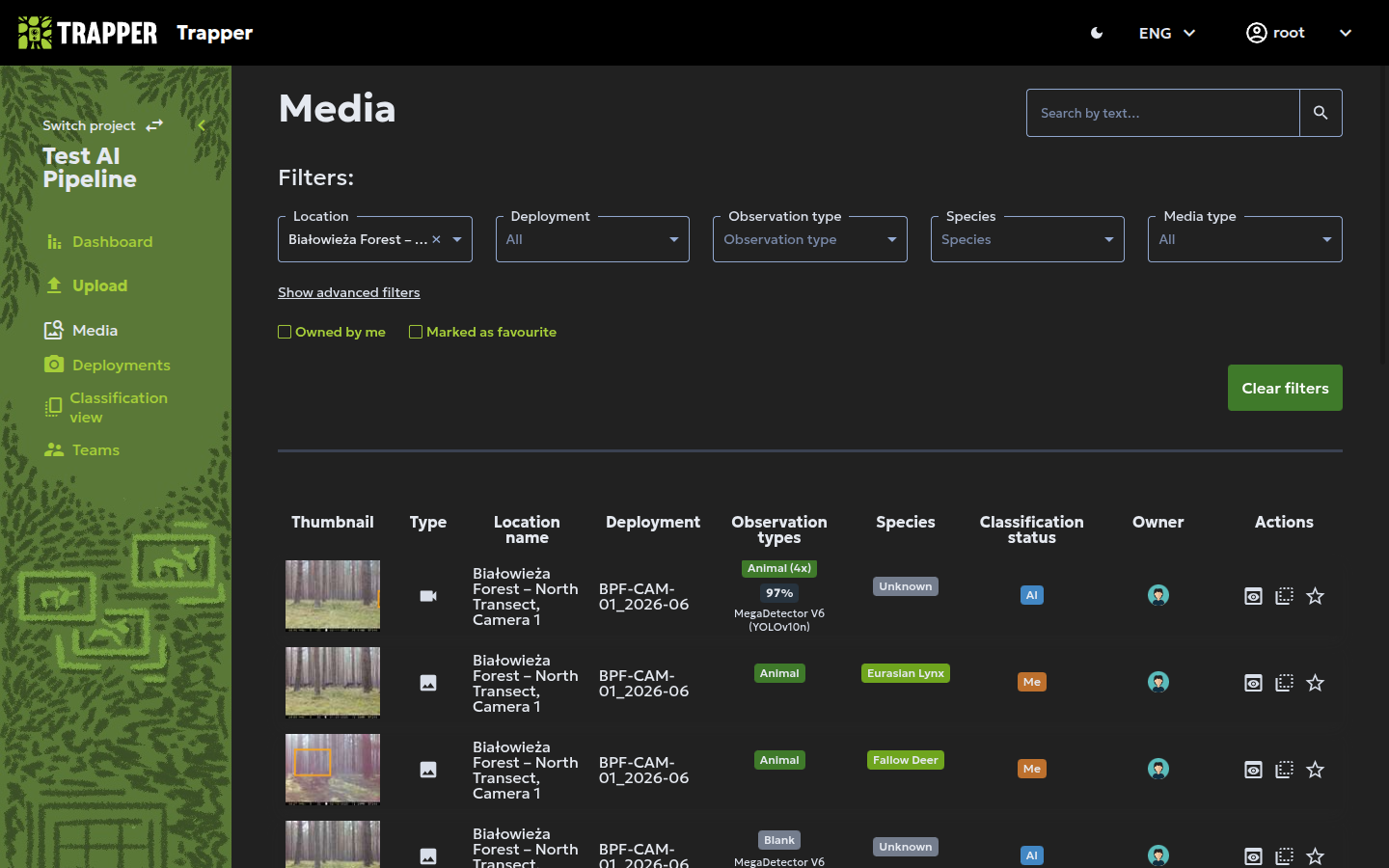
The Images / Media view¶
The Images tab (or Media when working with both images and videos) lets you browse and filter all media files available in the project. Each row represents a single media file and its associated observations (no detections, animals, humans, or vehicles).
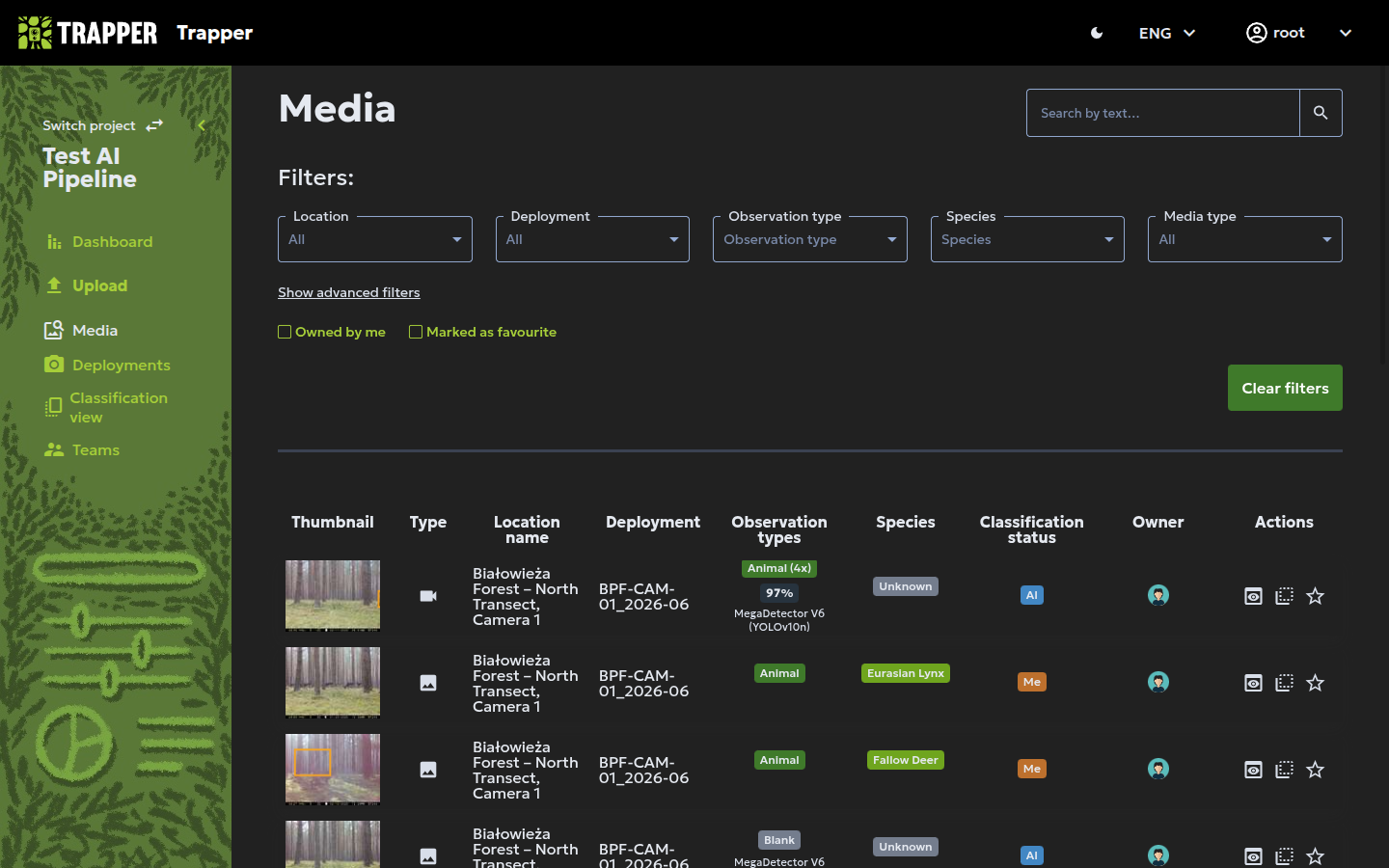
You can use the advanced filters at the top to narrow down the results by Deployment, Species, Shared by team, Observation type (e.g., Animal, Human, Vehicle), Sex, Age, and Classified by me.
The Image Viewer¶
Clicking on any observation opens the Image Viewer, which lets you:
- View the image with AI-generated bounding boxes and labels.
- Zoom in and out for a closer look.
- Adjust contrast, brightness, and saturation using the image filter tools to enhance visibility, especially in nighttime shots.
- Navigate between other images in the same sequence using the thumbnails at the bottom.
- View video files and play them directly in the viewer.
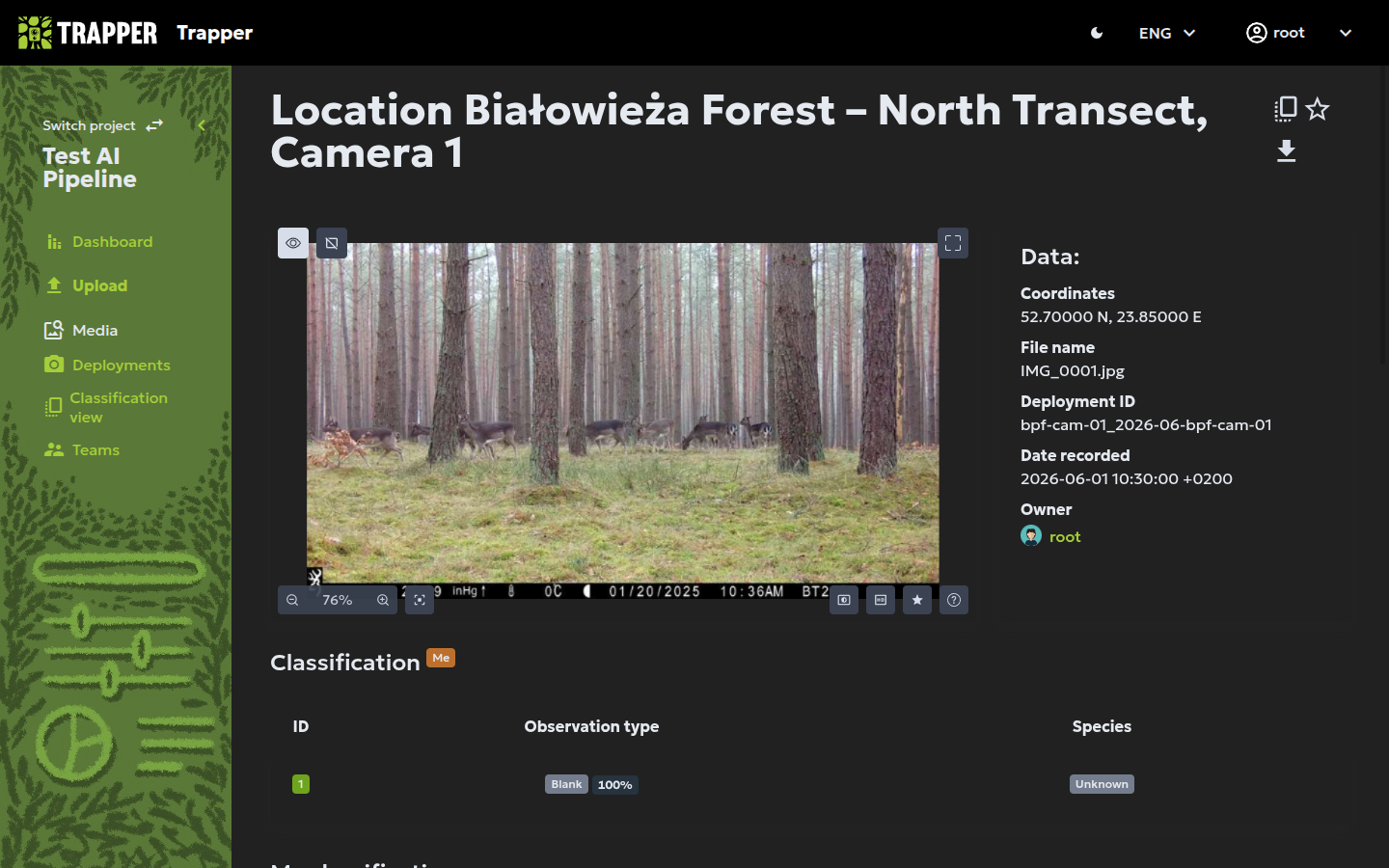
Classifying your first sequence¶
The Classification module is where you, the expert, review, correct, and validate the AI's work. This is the heart of the platform, designed for both precision and efficiency.
Navigating your data¶
The interface organises media into sequences.
What is a sequence?
A sequence is an ecological event — a group of images or videos that captures a continuous event, such as an animal or group of animals passing in front of the camera. The system automatically groups media into a sequence if captured within a configurable time window (default 5 minutes). This allows you to analyse a single event rather than many separate photos, which is crucial for tasks like counting unique individuals. Read more.
The interface provides efficient navigation at three levels:
- Single-object navigation — jump directly between annotated objects (click a bounding box or use keyboard shortcuts) to inspect or edit individual detections.
- Single-media navigation — move through images or videos using the next/previous controls or by selecting thumbnails in the sequence strip.
- Event/sequence navigation — navigate entire ecological events via the sequence strip, select multiple frames for group actions, or jump directly to a specific sequence or resource by entering its ID.
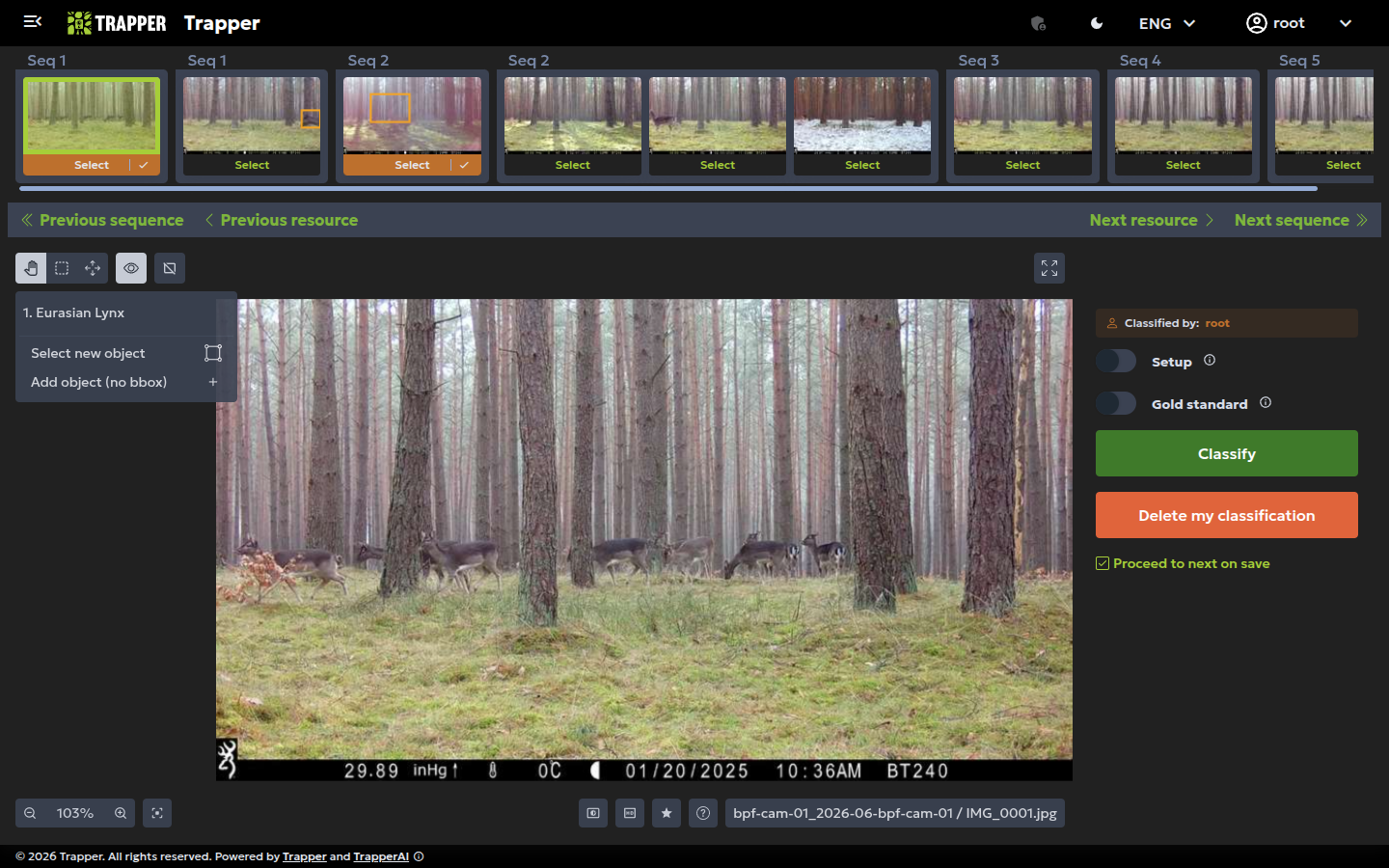
Keyboard shortcuts
The interface supports a variety of keyboard shortcuts for navigating between objects and images, zooming, and applying classifications. Press Ctrl + / (Cmd + / on macOS) to see the full list.
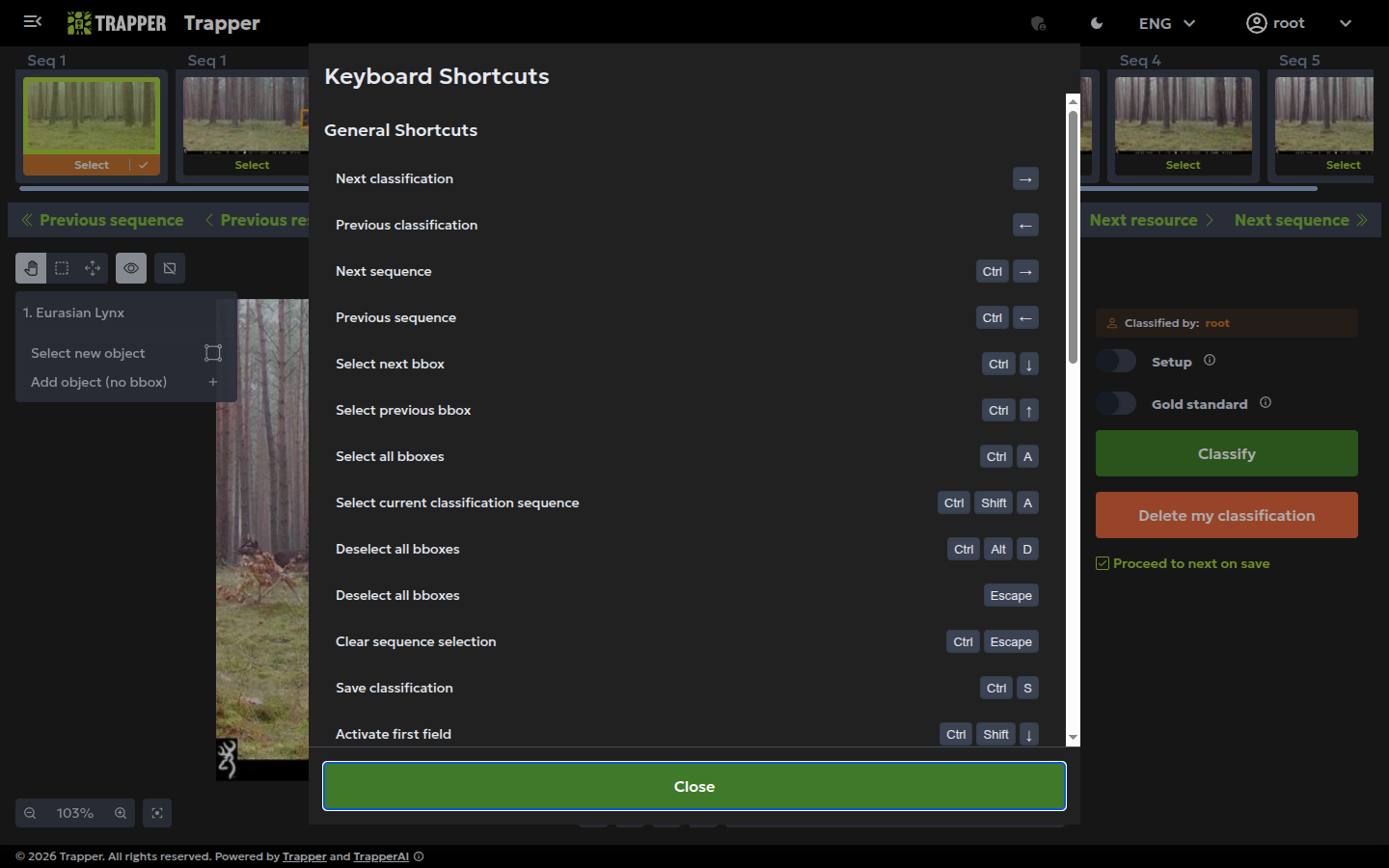
The interactive canvas and on-the-fly filters¶
The main image viewer is more than just a picture frame; it's an interactive canvas. This is your workspace for all annotation tasks. You can:
- Draw new bounding boxes by clicking and dragging.
- Select existing boxes to edit them.
- Resize and move boxes for a precise fit.
- Zoom and pan to inspect details anywhere on the image.
To help with classification, especially in challenging lighting conditions, you can use on-the-fly image filters. Sliders for Contrast, Brightness, and Saturation are available directly in the interface. Adjusting these can reveal details in dark infrared shots or correct overexposed daytime images, ensuring you never miss an important visual cue.
Flexible annotation modes¶
To accommodate different workflows and maximize speed, the interface supports multiple annotation modes:
| Mode | What it does |
|---|---|
| Single Object | Click one bounding box — opens the classification form for that specific object. Most precise. |
| All Objects on Image | Classify everything visible in the current view with one classification. |
| Group Classification (bulk) | Select multiple thumbnails in the sequence strip — any classification you apply covers all objects in all selected images. Fastest for uniform sequences. |
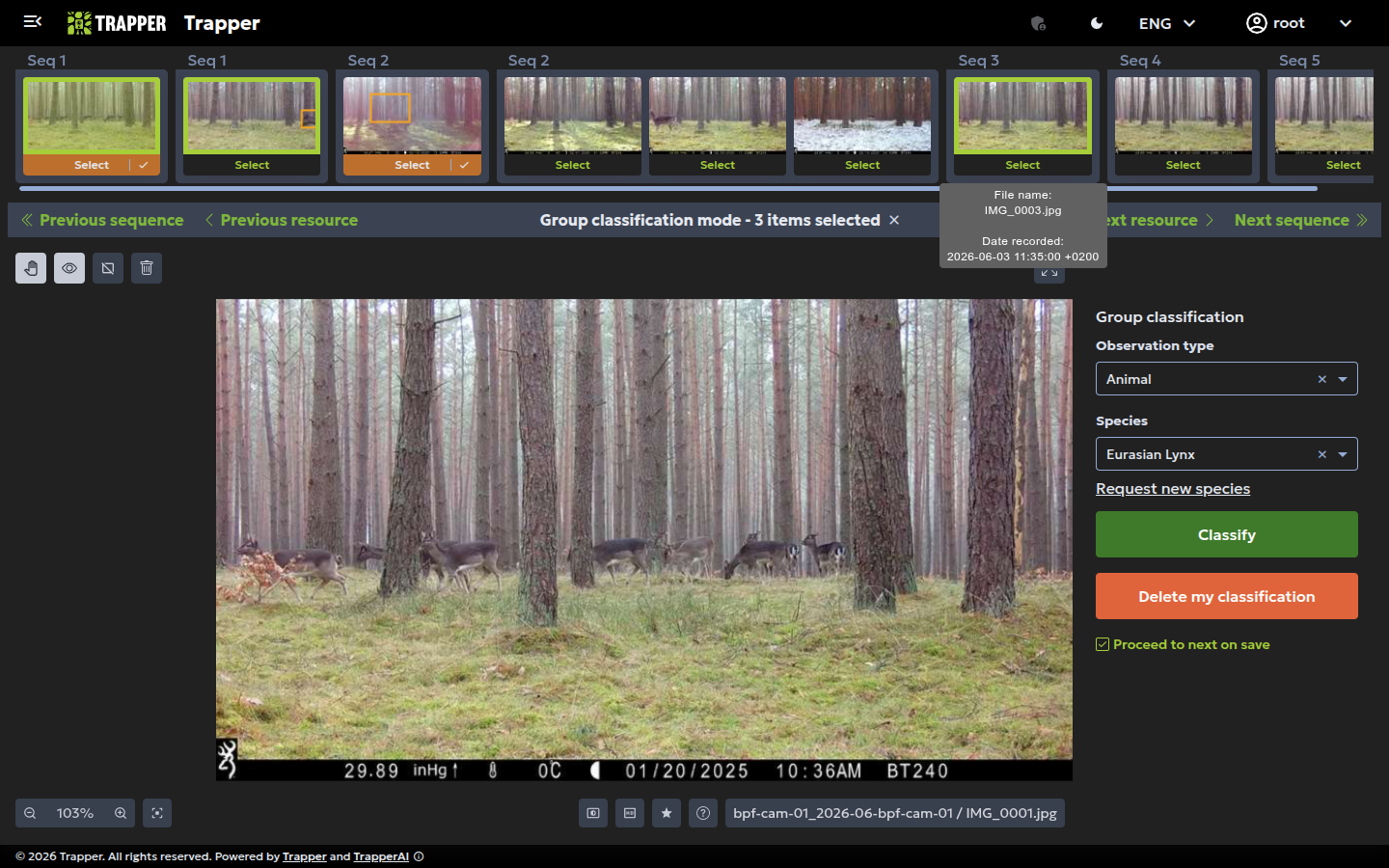
The project-specific classification form¶
When you select an object to classify, a form appears. This form is dynamic and project-specific.
Dynamic and project-specific
The fields you see (e.g., species, sex, age, number of individuals, behavior) are not hard-coded. They can be customized for each project by a project manager in the Trapper Expert module using a feature called the Classificator object. Some standardized fields are required for all classificators (for example observation_type and species), while others are optional (for example age and sex). All predefined fields conform to the Camtrap DP standard. Read more
The Classificator also allows you to define custom fields and assign a data type (e.g., string, integer, float, boolean) and validation rules. These settings enable automatic input validation in the UI to help ensure consistent, high-quality data. See the tutorial section 3. Build a Classificator for details.
For example, a project studying wolves might include custom metadata fields for howling_activity (boolean) and health_status (string | enum), while a project on roe deer might include fields for antler_development (boolean). This flexibility ensures that the data you collect is tailored to your research questions while remaining standardized for interoperability: all fields can be mapped to the Camtrap DP schema (e.g. custom fields can be exported as observationTags) so datasets are consistent, shareable, and machine‑readable across projects and platforms.
Managing teams & your profile¶
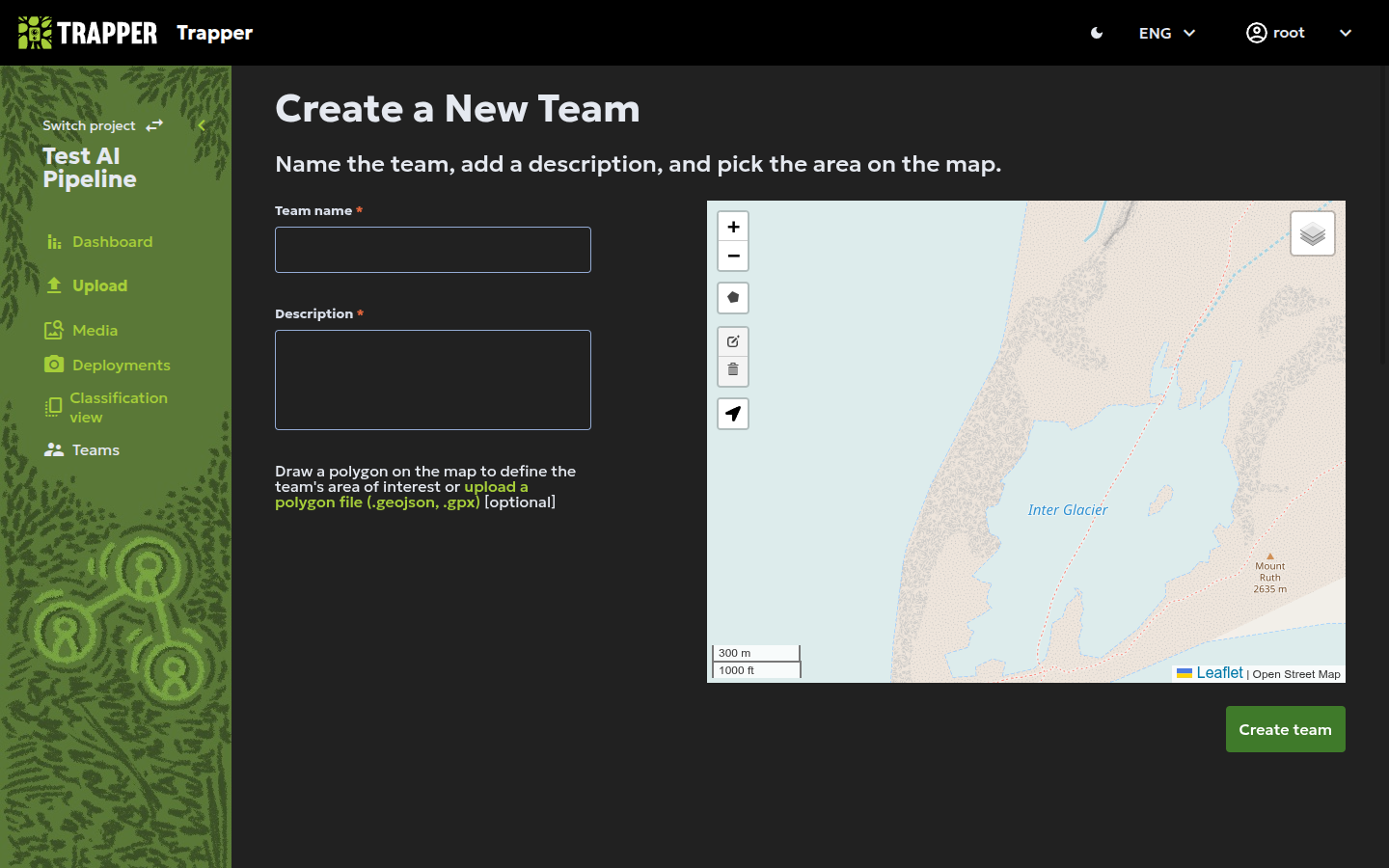
Creating a team¶
Collaboration is key! You can create teams to work on projects together. To share data and annotation efforts.
- Go to the Teams section and click to create a new one.
- Give your team a name and a description.
- Use the map tools to draw a polygon defining your team's primary area of interest. This helps organize your research efforts. You can also upload a GeoJSON or GPX file to define the area.
Note
Teams are a flexible self-organization tool for Trapper users — whether researchers, hunters, NGO staff, national park personnel, or volunteers — to coordinate fieldwork, share data and responsibilities, and organise annotation efforts. Teams support local collaboration while project permissions remain governed by administrators.
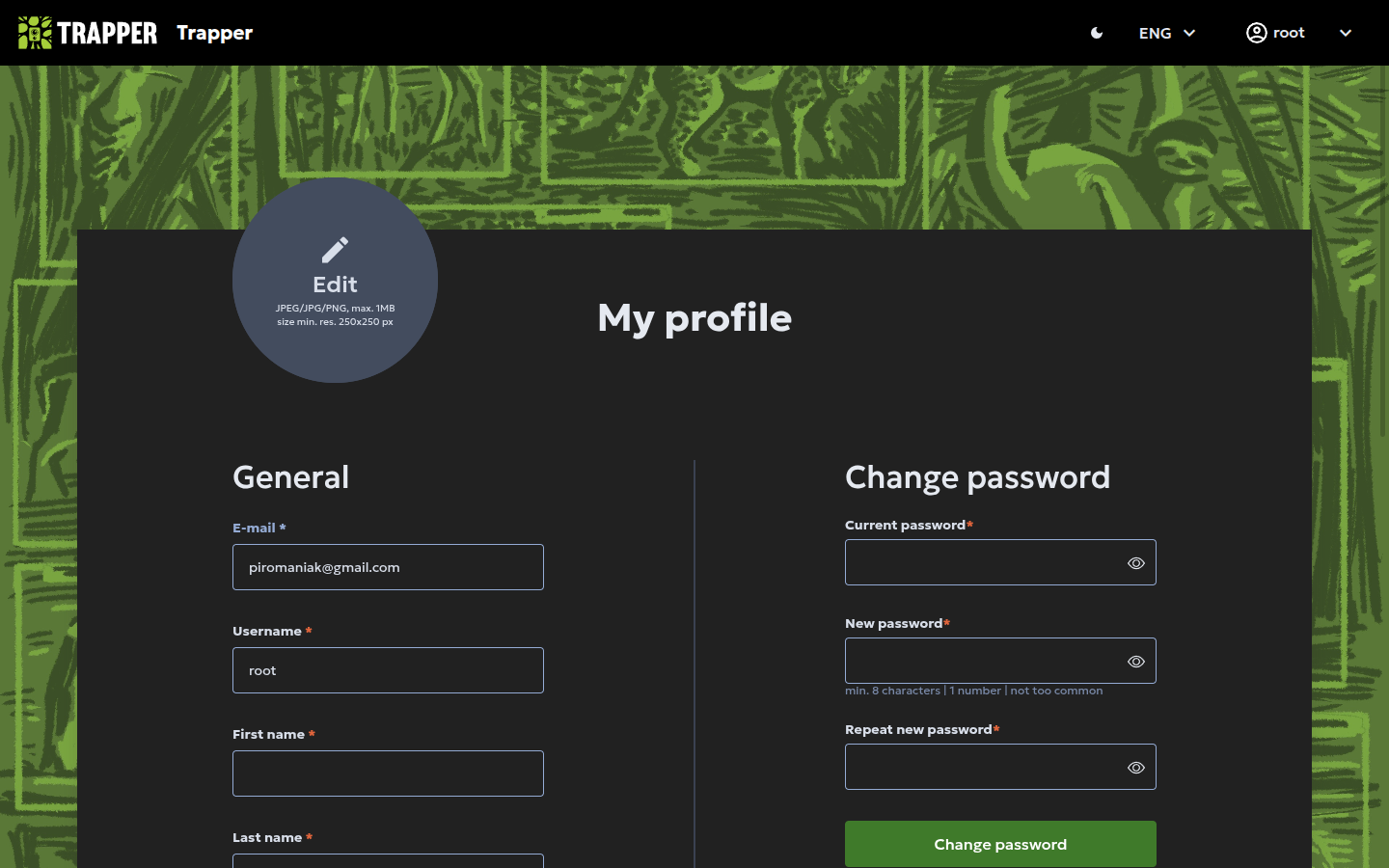
Profile and settings¶
Click your profile icon to manage your account:
- General — update your email, username, first name, last name, phone number, institution, and write a short bio.
- Change password — update your password for security.
- Multi-factor authentication — enable two-factor authentication for added account security.
- Delete account — remove your account permanently.
- Language — switch between English, Swedish, Polish, German, Czech, and Spanish.
You're now ready to master the Trapper Citizen Science Interface. Happy trapping! 📸🌲
Next steps¶
- Video annotation & interpolation — expert-mode annotation panel, per-frame timeline, interpolation, and all keyboard shortcuts for video sequences
- Bounding boxes for ML training data
- Create a classification project — for project managers configuring the Classificator and AI pipeline